Apache Spark به عنوان یک سیستم محاسبهی کلاستری سریع و همه منظوره، به ارائه APIهای سطح بالا در Java، Scala، Python و R و همچنین موتور بهینهشده ای میپردازد که از گرافهای اجرای متداول پشتیبانی مینماید. به علاوه، این سیستم از مجموعهی گستردهای از ابزارهای سطح بالاتر نظیر Spark SQL برای SQL و پردازش دادههای ساختار یافته، MLlib برای یادگیری ماشینی، GraphX برای پردازش گراف و همچنین Spark Streaming نیز پشتیبانی میکند. در این مقاله به بررسی برخی قابلیت های Spark می پردازیم.

Spark بر روی سیستمهای ویندوز و شبه یونیکسی (مانند Linux و Mac OS) قابل اجرا میباشد. به علاوه اجرای Local آن بر روی یک سیستم، کار سادهای خواهد بود؛تمام آنچه که نیاز دارید جاوای نصب شده روی System Path یامتغیر محیطیِ Java-Home است که به نصب Java اشاره میکند.
Spark بر روی +Java 7+, Python 2.6+, R 3.1 نیز اجرا میگردد. برای Spark 1.6.1 ،Spark API از Scala 2.10 استفاده میشود. شما باید از نسخههای سازگار Scala 2.10.x استفاده نمایید.
بررسی Cluster Mode و برخی قابلیت های Spark
در زیر، به مروری کلی نحوهی اجرای Spark بر روی کلاسترها میپردازیم تا شناسایی اجزای آن به راحتی انجام گردد.
اجزا یا Component
یکی از قابلیت های Spark که به آن می توان اشاره نمود آن است که برنامههای Spark به صورت مجموعه مستقلی از فرآیندها در یک کلاستر اجرا میشوند که از طریق SparkContext در برنامه اصلی (تحت عنوان Driver Program) تنظیم میگردند.
SparkContext این قابلیت را داراست که برای اجرا روی یک کلاستر، به انواع متعددی از Cluster Manager ها متصل گردد (مانند Mesos, Yarn, Spark’s Standalone Cluster Manager) بنابراین تخصیص منابع را برای برنامهها انجام میدهد. Spark در هنگام اتصال، Executorهایی بر روی Nodeها در کلاستر مییابد که در واقع فرآیندهایی هستند که محاسبات را انجام داده و دادهها را برای برنامه ذخیره مینمایند؛ و در مرحله بعد، کد برنامه را به Executorها ارسال نموده و در نهایت نیز SparkContext، وظایف (Task) را برای اجرا به Executorها میفرستد.
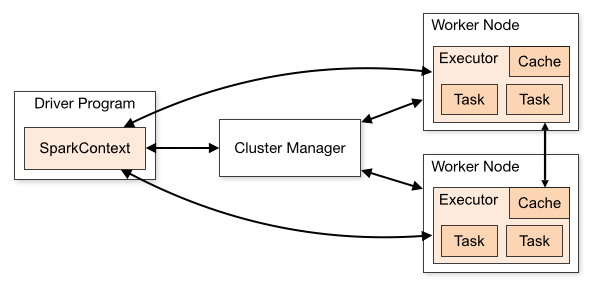
در زیر به ارائه برخی نکات مهم در مورد این معماری می پردازیم:
1-هر برنامه دارای فرآیندهای Executor مختص به خود میباشد که در تمام طول برنامه پابرجاست و وظایف را در چندین Thread انجام میدهد. این موضوع دارای مزیتِ تفکیک برنامهها از یکدیگر هم از لحاظ زمانبندی (هر یک از درایورها، وظایف خود را تعیین مینماید) و هم از نظر Executor (وظایفی از برنامههای مختلف در JVM های متفاوت) میباشد. به هرحال این بدان معناست که دادهها، بدون نوشتن آنها بر روی یک سیستم ذخیرهسازی خارجی در برنامههای مختلف Spark مانند SpartkContext، نمیتوانند Share شوند.
2-Spark به مدیریت کلاسترها وابسته نمی باشد و تا زمانی که قادر به دستیابی به فرآیندهای Executor باشد و این فرآیندها با یکدیگر در ارتباط باشند، اجرای آن حتی بر روی Cluster Manager که از برنامههای دیگر (مانند Mesos/YARN) نیز پشتیبانی مینماید، به راحتی امکان پذیر است.
3-Driver Program باید به ارتباطات ورودی و امکان پذیرش آنها از سمت Data Executorها را در طول عمر تعیین شده مورد بررسی قرار دهد، همچنین Driver Program باید از طریق شبکه قابل آدرس دهی برای Worker Node ها باشد.
4- با توجه به اینکه Driver ، وظایف کلاستر را تعیین مینماید، باید در نزدیکی Worker Nodeها و ترجیحا در همان شبکه Local اجرا شود. اگر قصد ارسال درخواست به کلاستر را به صورت Remote دارید، به جای اینکه Driver را دور از Worker Nodeها اجرا نمایید؛ باید یک RPC را برای Driver باز نموده و عملیاتها را از نزدیک Driver بفرستید.
انواع Cluster Manager
این سیستم در حال حاضر، سه Cluster Manager را پشتیبانی مینماید:
- Standalone: یک Cluster Manager ساده همراه با Spark که تنظیم کلاستر را تسهیل مینماید.
- Apache Mesos: یک Cluster Manager کلی یا عمومی که میتواند برنامههای سرویس و Hadoop MapReduce را نیز اجرا نماید.
- Hadoop YARN: یک Resource Manager درHadoop 2
به علاوه ایجاد کلاستر Standalone بر روی Amazon EC2 با اسکریپت های EC2 Launch مربوط به Spark تسهیل میگردد.
ارسال برنامه ها (Submitting Application)
برنامه ها را میتوان با استفاده از اسکریپت Spark-Submit برای یک کلاستر از هر نوعی ارسال نمود.
مانیتورینگ
هر Driver Program دارای یک رابط گرافیکی تحت وب است که روی پورت شماره 4040 قرار دارد و اطلاعاتی را در مورد اجرای وظایف، Executorها و استفاده از Storage نشان میدهد. میتوانید در مرورگر وب به آدرس http://<driver-node>:4040 مراجعه نمایید تا به این UI دسترسی پیدا کنید.
زمانبندی Jobها یا Job Scheduling
Spark، میتواند فرآیند تخصیص منابعِ پیرامون (در سطح Cluster Manager) و داخل برنامه (در صورتی که محاسبات متعددی در یک SparkContext صورت گیرد) را کنترل نماید.
در جدول زیر، اصطلاحات تخصصی و مفاهیم کلاستر ارائه گردیده است:
| واژگان | توضیحات |
|---|---|
| برنامه | برنامه کاربر که روی Spark ایجاد میشود و شامل Driver Program و Executorها در کلاستر است. |
| Application Jar | Jar در برگیرندهی برنامهی Spark کاربر است. در برخی موارد کاربران قصد دارند یک Uber Jar ایجاد کنند که برنامهها و موارد وابسته به آن را در بر گیرد. Jar مختص کاربر هیچگاه شامل کتابخانه Spark یا Hadoop نمیشود؛ با این وجود در Runtime این موارد اضافه میگردند. |
| Driver Program | فرآیندی که تابع اصلی برنامه را اجرا و SparkContext را ایجاد مینماید. |
| Cluster Manager | یک سرویس خارجی برای دستیابی به منابع کلاستر (مانند Standalone Manager, Mesos, Yarn) می باشد. |
| Deploy Mode | در هنگام اجرای فرآیند درایور مشخص میگردد. درCluster Mode، درایور توسط Framework در داخل کلاستر Launch میگردد. در Client Mode نیز Submitter، درایور را خارج از کلاستر Launch مینماید. |
| Worker Node | هر Nodeی که بتواند کد برنامه را در کلاستر اجرا نماید. |
| Executor | فرآیندی که برای یک برنامه در Worker Node آغاز میشود، وظایف را اجرا نموده و دادهها را در حافظه Disk Storage نگهداری مینماید. هر برنامه دارای Executor مخصوص به خود میباشد. |
| Task | یک واحد کار یا وظیفه که برای Executor ارسال میگردد. |
| Job | یک محاسبه متقارن که شامل وظایف متعددی است و در پاسخ به عملکرد Spark (مانند Save, Collect) ایجاد میگردد. ملاحظه خواهید کرد که این واژه در Driver’s Logها به کار میرود. |
| Stage | هر Job به مجموعههای کوچکتری از Task یا وظایف تقسیم میگردد که Stage نام دارند و به یکدیگر وابسته میباشند؛ ملاحظه خواهید کرد که این واژه در Driver’s Log ها استفاده میشود. |
