مفهوم الگوریتم در دادهکاوی (Data Mining) و یا در یادگیری ماشینی (Machine Learning) به مجموعهای از استنتاجها و محاسبات اطلاق میشود که مدلی از دادهها را ارائه مینماید. به منظور ایجاد مدل، در ابتدا الگوریتم به آنالیز دادههای ارائه شده میپردازد تا انواع خاصی از الگوها یا روندها را جستجو نماید. سپس از نتایج این آنالیز به دفعات استفاده میکند تا به پارامترهای مطلوب برای ایجاد مدل دادهکاوی دست یابد. در مرحلهی بعد این پارامترها جهت استخراج الگوهای عملیاتی و فرآیندهای آماری دقیق در تمامی مجموعه داده به کار گرفته میشوند.

مدل دادهکاوی تهیه شده از دادههای کاربر توسط یک الگوریتم در قالبهای مختلفی شکل میگیرد که برخی از آنها عبارتند از:
- مجموعهای از کلاسترها که نحوه ارتباط موارد مختلف در یک مجموعهداده را توصیف میکند.
- درخت تصمیمگیری که نتایج را پیشبینی نموده و چگونگی اثرگذاری معیارهای مختلف بر این نتیجه را توضیح میدهد.
- یک مدل ریاضیاتی که میزان فروش را پیشبینی مینماید.
- مجموعهای از قواعد که چگونگی گروهبندی محصولات در یک تراکنش و احتمال خریداری همزمان آنها را توصیف میکند.
الگوریتم ارائه شده در SQL Server Data Mining (که در مقالات قبلی سایت به آن پرداخته شد) به عنوان پرطرفدارترین روش برای کشف الگوی دادهها شناخته میشود که تحقیق و بررسی زیادی بر روی آن صورت گرفته است. به عنوان مثال K-Means Clustering به عنوان یکی از قدیمیترین الگوریتمهای Clustering محسوب شده و در بسیاری از ابزارها و برای نسخههای مختلفِ پیادهسازی و Optionها در سطح گستردهای بهکار میرود. شیوههای خاصی از Clustering K-Means که در SQL Server Data Mining مورد استفاده قرار میگیرد، از سوی مرکز تحقیقات مایکروسافت ارائه شده و سپس برای عملکرد با سرویسهای آنالیز بهینهسازی شده میگردد. همچنین تمامی الگوریتمهای دادهکاوی مایکروسافت را میتوان با استفاده از APIهای موجود تا حد زیادی سفارشیسازی نمود و یا حتی به طور کامل برنامهریزی کرد. علاوه بر این موارد میتوان فرآیند ایجاد، آموزش و حفظ مدلها را با استفاده از Componentهای دادهکاوی در Integration Services خودکارسازی نمود.
در ضمن میتوان از انواع الگوریتمهای Third-Party نیز استفاده نمود که با OLE DB در مورد خصوصیات دادهکاوی سازگاری دارند و یا حتی میتوان الگوریتمهایی سفارشی ایجاد نمود که در قالب سرویس ثبت گردیده و سپس در چارچوب SQL Server Data Mining بهکارگرفته میشوند.
انتخاب الگوریتم صحیح
انتخاب مناسبترین الگوریتم برای هر یک فرآیندهای تحلیلی خاص یکی از چالشهای اساسی پیش روی متخصصان این حوزه میباشد. با وجودی که میتوان از الگوریتمهای مختلفی برای انجام فعالیتهای مشابه در کسبوکار استفاده نمود اما ممکن است هر الگوریتم به نتیجهی متفاوتی رسیده و یا حتی برخی از این الگوریتمها بیش از یک نتیجه را در بر داشته باشد . برای مثال میتوان از الگوریتم درختهای تصمیمگیری مایکروسافت (Microsoft Decision Trees) نه تنها برای پیشبینی بلکه به عنوان روشی برای کاهش تعداد ستونها در یک مجموعه داده استفاده نمود، زیرا این درخت تصمیمگیری میتواند ستونهایی را شناسایی کند که بر روی مدل نهایی دادهکاوی تاثیری ندارند.
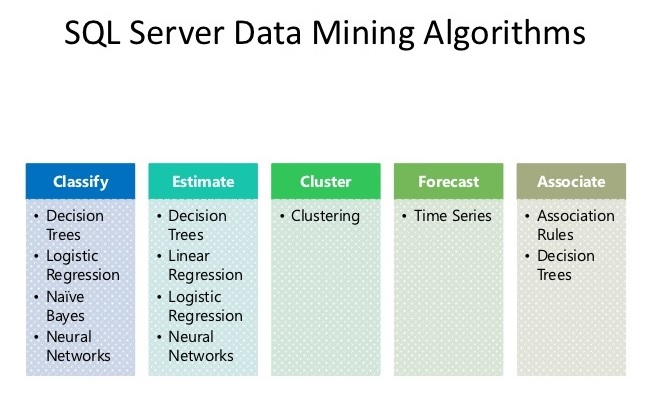
انتخاب الگوریتمها بر اساس نوع آن
الگوریتمهای مورد استفاده در SQL Server Data Mining شامل موارد زیر میگردد:
-
الگوریتمهای دستهبندی (Classification):
پیشبینی یک یا چند متغیر مستقل بر اساس سایر مشخصهها در مجموعه داده
-
الگوریتمهای رگرسیون (Regression):
پیشبینی یک یا چند متغیر عددی پیوسته از جمله سود یا ضرر بر اساس سایر ویژگیهای مجموعه داده
-
الگوریتمهای بخشبندی (Segmentation):
دادههای دارای ویژگیهای مشابه را در قالب گروه یا کلاستر تقسیمبندی مینماید.
-
الگوریتمهای رابطهای (Association):
روابط بین ویژگیهای مختلف در یک مجموعه داده را شناسایی میکند. رایجترین کاربرد این نوع الگوریتم در ارائه قواعد مربوط به روابط میباشد که در تحلیل و بررسی بازار قابل استفاده میباشد.
-
الگوریتمهای آنالیز توالی (Sequence analysis):
ارائهی یک جمعبندی از بخشها یا توالیهای مکرر در دادهها که از آن جمله میتوان به تعداد کلیکهای وبسایت یا تعداد Event Logها پیش از نگهداری سیستم اشاره نمود.
در هر صورت هیچ دلیلی وجود ندارد که کاربران برای استفاده از یک الگوریتم در راهکارهای مختلف با محدودیت روبرو شوند. برای مثال ممکن است تحلیلگران باتجربه از یک الگوریتم مشخص برای تعیین اثربخشترین دادههای ورودی (مانند متغیرها) استفاده نمایند و سپس با استفاده از الگوریتم دیگری به پیشبینی نتیجه خاصی بر اساس این دادهها بپردازند. SQL Server Data Mining این امکان را برای کاربران فراهم مینماید تا مدلهای مختلفی را بر اساس یک ساختار دادهکاوی واحد ارائه نمایند؛ بنابراین در یک راهکار دادهکاوی واحد میتوان از مواردی همچون الگوریتم Clustering، مدل درخت تصمیمگیری و مدل Naive Bayes استفاده نمود تا به دیدگاههای متفاوتی نسبت به دادهها دست یافت. به علاوه این امکان وجود دارد که برای انجام امور جداگانه از چندین الگوریتم مختلف در یک راهکار واحد استفاده شود. به عنوان مثال میتوان از تحلیل رگرسیون برای پیشبینیهای مالی و یا از الگوریتم شبکهی عصبی (Neural Network Algorithm) برای آنالیز فاکتورهای موثر بر پیشبینی استفاده نمود.
