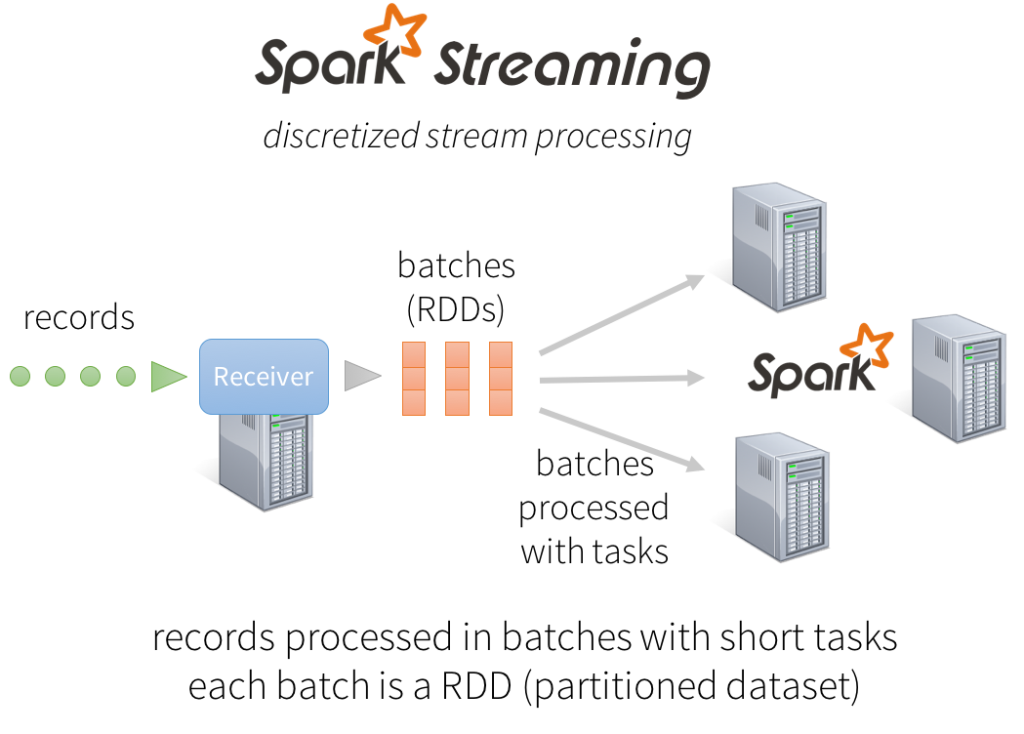
درک مفاهیم ارائه شده توسط Spark Streaming به کاربران این اجازه را میدهد تا روش پیادهسازی Fault-Tolerance در Resilient Distributed Datasets یا به اختصار RDDهای Spark را به خاطر بسپارند.

1- RDDبه مجموعهای از دادههای توزیعی و بدون تغییر با قابلیت محاسبه مجدد، اطلاق میشود. هر RDD این قابلیت را دارد که ترتیبی از عملیاتهای قطعی و مشخص را داشته باشد که برای ایجاد RDD در مجموعهای از دادههای ورودی دارای قابلیت تحمل خطا یا Fault-Tolerant به کار برده میشوند.
2- در صورت از دست رفتن هر یک از بخشهای RDD به دلیل خرابی Node در حال سرویسدهی این امکان وجود دارد که این بخش با استفاده از فرایند ردهبندی عملیاتها از مجموعه اصلی دادههای دارای قابلیت Fault Tolerance یا به اختصار FT مجددا پردازش مجدد شود.
3- با فرض اینکه تمامی تغییرات در RDD به صورت قطعی صورت میگیرد، دادههای موجود در نسخه نهایی و تغییریافته RDD، علیرغم بروز خرابی در کلاستر Spark همچنان یکسان خواهند بود.
Spark بر روی دادههای موجود در فایلسیستمهای دارای قابلیت FT مانند HDFS یا S3 فعال میشود؛ بنابراین تمام RDDهای ایجادشده از دادههای FT نیز دارای این ویژگی تحمل خطا خواهند بود. با این وجود این موضوع درباره Spark Streaming صدق نمیکند، زیرا دادهها در اکثر موارد از طریق شبکه دریافت میشوند (به استثنای مواردی که از FileStream استفاده میشود). به منظور آنکه ویژگیهای یکسانی از Fault-Tolerance در تمامی RDDهای ایجاد شده به دست آید، انجام Replication دادههای دریافتی بین چندین اجرا کننده Spark در Nodeهای عملیاتی کلاستر ضرورت مییابد (فاکتور پیشفرض Replication 2 است). بدین ترتیب، دو نوع داده در سیستم وجود دارد که بازیابی آن در صورت بروز خرابی ضرورت مییابد:
1- دادههای دریافت شده و Replicateشده: این دسته از دادهها در صورت خرابی یک Node عملیاتی از آسیب محفوظ میباشند زیرا یک نسخه از آن بر روی یکی دیگر از Nodeها وجود دارد.
2- دادههای دریافتی اما Bufferشده برای Replication: به دلیل عدم انجام عملیات Replication برای این دسته از دادهها، بازیابی آنها تنها از طریق دریافت مجدد از منبع امکانپذیر میباشد.
علاوه بر نکات ذکرشده، دو نوع خرابی زیر نیز باید مورد توجه جدی قرار گیرد:
1- خرابی Node عملیاتی: این احتمال وجود دارد که هر یک از Nodeهای عملیاتی دچار خرابی شده و تمام دادههای In-Memory موجود در آن از دست برود. در صورت فعالیت هر یک از دریافتکنندهها بر روی این Nodeهای خراب، دادههای Bufferشده (بدون نسخهی پشتیبان) از دست خواهد رفت.
2- خرابی Driver Node: در صورتی که Node فعال در برنامه کاربردی Spark Streaming دچار خرابی شود، SparkContext از دست رفته و در نتیجه آن نیز تمامی Executorها و دادههای In-Memory آنها از دست خواهد رفت.
آشنایی با مفاهیم FT در Spark Streaming
معمولا تعداد مراحل در سیستمهای Streaming برمبنای تعداد دفعات پردازش هر یک از رکوردها توسط سیستم بهدست میآید. لازم به ذکر است که سه نوع گارانتی برای یک سیستم وجود دارد که علیرغم بُروز خرابی در شرایط عملیاتی احتمالی ارائه میگردد:
1- حداکثر یکبار: هر رکورد تنها یکبار پردازش شده و یا هرگز پردازش نمیشود.
2- حداقل یکبار: هر رکورد یک یا چند بار پردازش میشود. این حالت قویتر از حالت قبل میباشد زیرا حفظ دادهها و از دست نرفتن آن را تضمین مینماید. اما در هر حال ممکن است نسخههای تکراری وجود داشته باشد.
3- دقیقا یکبار: هر رکورد دقیقا یک بار پردازش میشود. در این شرایط دادهها از دست نرفته و هیچ دادهای به دفعات پردازش نمیشود. بنابراین این حالت، قویترین نوع گارانتی را نسبت به سایر موارد ارائه مینماید.
مفاهیم کاربردی
به طور کلی در تمامی سیستمهای پردازش Stream، سه مرحله برای پردازش دادهها وجود دارد:
1- دریافت دادهها: دادهها با استفاده از گیرنده یا روشهای دیگری از منابع دریافت میشود.
2- تغییر دادهها: دادههای دریافتی با استفاده از شیوههای تبدیل DStream و RDD تغییر مییابند.
3- خروج دادهها: دادههای تغییریافته در نهایت به سیستمهای خارجی مانند فایلسیستمها، پایگاههای داده، داشبوردها و غیره ارسال میشوند.
چنانچه یک برنامهکاربردی Streaming نیاز به کسب گارانتی End-to-End فقط برای یکبار داشته باشد، هر یک از مراحل نیز باید گارانتی “دقیقا یکبار” را ارائه نماید. بدین معنا که هر رکوردی باید دقیقا یکبار دریافت شده و تغییر یابد و در نهایت نیز یکبار به سیستمهای Downstream ارسال گردد. مفاهیم مربوط به این مراحل در ساختار Spark Streaming به صورت زیر میباشد:
1- دریافت دادهها: منابع ورودی مختلف میتوانند گارانتیهای متفاوتی را ارائه نمایند.
2- تغییر دادهها: کلیه دادههای دریافت شده دقیقا یکبار پردازش میشوند. ضمن اینکه در صورت بُروز خرابی حتی اگر این دادهها در دسترس باشند، RDDهای تغییریافته درنهایت دارای محتوای یکسانی خواهند بود.
3- خروجی دادهها: عملیاتهای خروجی به صورت پیشفرض گارانتی “حداقل یک بار” را تضمین میکنند؛ زیرا به نوع عملیات خروجی (تغییریافته یا تغییرنیافته) و حالت سیستم Downstream (پشتیبانی یا عدم پشتیبانی از تراکنشها) وابسته میباشند. با این حال کاربران میتوانند مکانیسم تراکنشی مختص خود را اجرا نمایند تا به گارانتی “دقیقا یکبار” دست یابند.
مفاهیم مربوط به دادههای دریافتی
منابع ورودی مختلف به ارائه گارانتیهای متفاوتی مانند “حداقل یکبار” و “دقیقا یکبار” میپردازد.
- همراه با فایلها
در صورت ارائه تمامی دادههای ورودی در یک فایل سیستم مانند HDFS که از قابلیت FT برخوردار است، Spark Streaming میتواند تمامی دادهها را بازیابی و پردازش نموده و به این ترتیب گارانتی”دقیقا یکبار” را ایجاد نماید؛ با این مفهوم که صرفنظر از نوع خرابی، تمام دادهها دقیقا یکبار پردازش میشوند.
- همراه با منابع مرتبط با گیرنده
معیارهای تحمل خطا برای منابع ورودی مرتبط با گیرنده (Receiver)، به سناریوی خرابی و نوع Receiver بستگی دارد. لازم به ذکر است که دو نوع گیرنده وجود دارد:
1- گیرنده قابل اطمینان: این دسته از گیرندهها صرفا پس از حصول اطمینان از ایجاد نسخه تکراری از دادههای دریافتی میتوانند منابع قابل اطمینان را تایید نمایند. در صورت بروز خرابی در این نوع Receiver، تایید دادههای Bufferشده (Replicate نشده) توسط منبع دریافت نمیشود؛ بنابراین در صورت Restart نمودن گیرنده، مجددا دادهها توسط منبع ارسال شده و هیچ دادهای به دلیل بروز خرابی از دست نمیرود.
2- گیرندههای غیر قابل اطمینان: به دلیل عدم ارسال تایید از سوی این نوع گیرنده، امکان از دست رفتن دادهها در صورت خرابیWorker یا Driver وجود دارد.
با توجه به نوع گیرنده مورد استفاده میتوان به گارانتیهای زیر دست یافت:
در صورت استفاده از گیرندههای قابل اطمینان، هیچ دادهای با خرابی Node از دست نمیرود. این در حالی است که با استفاده از گیرندههای غیرقابل اطمینان، امکان از دست رفتن دادههای دریافتیِ فاقد نسخه کپی وجود خواهد داشت. در صورت خرابی Driver Node علاوه بر از دست دادن دادههای فوق، این احتمال وجود دارد که تمامی دادههای قبلی که به صورت In-Memory دریافت و کپیبرداری شدهاند، از دست رود که این موضوع بر نتایج تغییرات Stateful نیز تاثیرگذار است.
Spark 1.2 برای محافظت از دادههای دریافت شده قبلی به ارائه تکنیک Write-Ahead Log میپردازد و دادههای دریافت شده را در Storage دارای قابلیت FT ذخیره مینماید. احتمال از دست رفتن دادهها با بهرهگیری از گیرندههای قابل اطمینان و فعالسازی Write-Ahead Log به صفر میرسد. این تکنیک میتواند گارانتی “حداقل یکبار” را ارائه نماید.
جدول زیر، خلاصهای از حالتهای مختلف پشتیبانی از FT در زمان خرابیها را نشان میدهد:
| سناریوی پیادهسازی | خرابی Worker | خرابی Driver |
|
|
|
|
|
|
