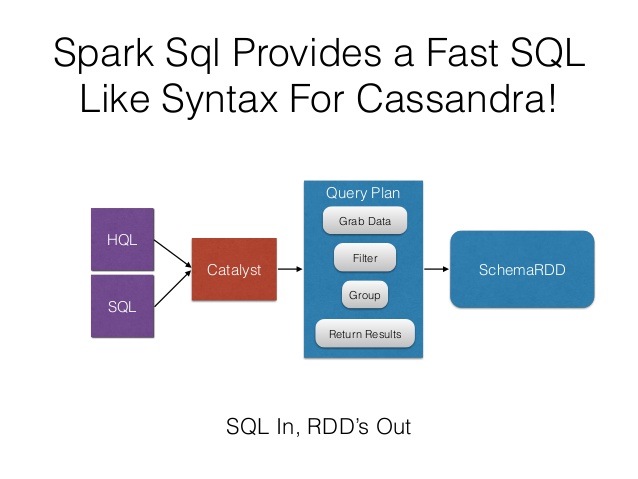
در واقع Spark SQL، یک ماژول Spark برای پردازش دادههای ساختاریافته به شمار میرود. برخلاف Spark RDD API یا به عبارتی Resilient Distributed Dataset، واسطهای کاربری ارائه شده توسط Spark SQL به ارائه اطلاعات بیشتری دربارهی ساختار دادهها و محاسبات اجرا شده برای Spark میپردازند و Spark SQL نیز به صورت داخلی از این اطلاعات برای ایجاد بهینهسازیهای بیشتر استفاده مینماید. روشهای متعددی برای ایجاد تعامل با Spark SQL وجود دارند که از جمله آنها میتوان به SQL، DataFrames API و Datasets API اشاره کرد. در هنگام بررسی نتایج، از موتور اجرای مشابهی استفاده میشود که مستقل از API یا زبان مورد استفاده برای ارائهی محاسبات میباشد. این یکپارچگی بدین معناست که توسعهدهندگان میتوانند به سادگی بین APIهای مختلف و بر اساس اینکه کدامیک طبیعیترین روش را برای ایجاد یک تغییر خاص فراهم مینماید، جا به جا شوند.

استفاده از SQL در Spark
یکی از کاربردهای Spark SQL آن است که Queryهای نوشتهشده با فرمت استاندارد SQL و یا HiveSQL را اجرا نمایند. به علاوه اینکه Spark SQL را میتوان برای خواندن دادههای Hive موجود نیز استفاده نمود. هنگامی که SQL در زبان برنامهنویسی دیگری اجرا میشود، نتایج به عنوان یک DataFrame ارائه میشوند؛ ضمن اینکه امکان برقراری تعامل با واسط کاربری SQL با استفاده از Command-Line یا JDBC/ODBC نیز وجود دارد.
DataFrame در Spark چیست؟
DataFrame، یک مجموعهی توزیعی (Distributed) از دادههای سازمانیافته در ستونهای نامگذاریشده میباشد. در واقع مفهوم آن را میتوان معادل جدول در پایگاه دادهی رابطهای یا Data Frame در R/Python دانست، با این تفاوت که بهینهسازی DataFrame از کیفیت بالاتری برخوردار میباشد. DataFrameها را میتوان از مجموعه گستردهای از منابع مانند Data Fileهای ساختاریافته، جداول موجود در Hive، پایگاههای داده خارجی یا RDDهای موجود ایجاد نمود. لازم به ذکر است که DataFrame API در زبانهای Scala، Java، Python و R قابل دسترسی میباشد.
تعریف Dataset در Spark
Dataset به عنوان یک واسط کاربری جدید و آزمایشی به حساب میآید که به Spark 1.6 افزوده شده و مزایای RDDها از جمله تایپ سریع، به کارگیری عملکردهای قدرتمند Lambda و مزایای موتور اجرای بهینهی Spark SQLها را در برمیگیرد. در ضمن این امکان نیز وجود دارد که Dataset از Objectهای JVM ایجاد شده و سپس با استفاده از تغییرات عملکردی از قبیل Map، FlatMap و Filter و … کنترل گردد.
Dataset API یکپارچه را میتوان در هردو زبان Scala و Java به کار گرفت. با اینکه Python قادر به پشتیبانی از Dataset API نمیباشد اما بسیاری از مزایای قبلی به دلیل ماهیت Dynamic آن وجود دارد. شایان ذکر است که پشتیبانی کامل Python، در نسخهی بعدی نیز وجود خواهد داشت.
تعاملپذیری با (RDD (Resilient Distributed Dataset
Spark SQL از دو روش مختلف برای تبدیل RDDهای موجود به DataFrameها پشتیبانی مینماید. در روش اول از فرآیند Reflection برای دستیابی به طرح RDD استفاده میشود که شامل انواع خاصی از Objectها میباشد. این رویکرد به ایجاد یک کد دقیقتر کمک میکند و علاوه بر عملکرد مطلوب با فراهم نمودن امکان آگاهی از طرح، موجب تسهیل روند برنامهنویسی برای برنامههای کاربردی Spark میگردد.
روش دوم برای ایجاد DataFrame از طریق یک واسط کاربریِ نرمافزاری صورت میگیرد که ایجاد یک طرح و سپس به کارگیری آن برای RDD موجود را امکانپذیر مینماید. این روش علیرغم طولانی بودن، به کاربران امکان ساخت DataFrameها را در شرایطی میدهد که ستونها و انواع آن تا زمان Runtime ناشناخته باقی میمانند.
ارائه طرح RDD با استفاده از فرآیند Reflection
واسط کاربری Scala برای Spark SQL به صورت خودکار از فرآیند تبدیل یک RDD متشکل ازCase Classهای (Case Class به تعریف طرح جدول میپردازد) مختلف به یک DataFrame پشتیبانی میکند. اسامی مربوط به مبحث Case Classها با استفاده از Reflection خوانده شده و به اسامی ستونها تبدیل میشود. علاوه بر این، Case Classها ممکن است شامل برخی انواع پیچیده همچون Sequenceها یا Arrayها گردند. این RDD به صورت ضمنی تبدیل به یک DataFrame شده و سپس به عنوان یک جدول ثبت میگردد که این جداول را میتوان در Statementهای SQL مورد استفاده قرار داد.
بررسی منابع داده
Spark SQL به پشتیبانی از عملکردِ طیف وسیعی از منابع داده گوناگون از طریق DataFrame میپردازد. این امکان وجود دارد که DataFrame به عنوان RDD نرمال عمل نموده و به عنوان یک جدول موقت نیز قابلیت Register داشته باشد. کاربر با Register نمودن یک DataFrame در قالب جدول میتواند اجرای Queryهای SQL را بر روی دادهها میسر نماید. در این بخش به توصیف روشهای کلی برای بارگذاری و ذخیرهی دادهها با استفاده از Spark Data Sources پرداخته میشود و سپس برخی گزینههای خاص موجود برای منابع دادهی Built-In معرفی میگردند.
تبدیل جدول Hive Metastore Parquet
Spark SQL در هنگام خواندن و نوشتن در جدولهای Hive Metastore Parquet، تلاش میکند تا برای ایجاد عملکرد بهتر، پشتیبانی Parquet مربوط به خود را جایگزین Hive SerDe نماید. این وضعیت از طریق پیکربندی “spark.sql.hive.convertMetastoreParquet” کنترل شده و به صورت پیشفرض فعال میگردد.
تلفیقی از Schemaهای Hive و Parquet
از نقطه نظر پردازش طرح (Schema) جدول، دو تفاوت کلیدی بین Hive و Parquet وجود دارد:
1- Hive به صورت Case Sensitive نبوده و از آن تاثیر نمیپذیرد، درحالیکه Parquet اینگونه نیست.
2- Hive میتواند تمامی Columnها را به صورت Nullable در نظر گیرد، درحالیکه قابلیت Nullability در Parquet حائز اهمیت بسیاری است.
به همین دلیل باید در هنگام Convert نمودن یک جدول Hive Metastore Parquet به جدولSpark SQL Parquet، به Reconcile نمودن Schema Hive Metastore و Schema Parquet توجه نمود. این فرایند طبق قواعد زیر صورت میگیرد:
1- فیلدهایی که دارای نام مشابه در Schema باشند، صرفنظر از وضعیت Nullability باید دارای نوع مشابهی از داده باشند. فیلدهای Reconcile شده باید دارای دادههایی از سمت Parquet باشد تا به این ترتیب، وضعیت Nullability آنها حفظ گردد.
2- Schema پس از Reconcile دقیقا شامل فیلدهای تعریفشده در Schema Hive Metastore میگردد.
- هر یک از فیلدهایی که صرفا در Parquet Schema موجود میباشند، در Schema به صورت Reconcile شده نیز گنجانده میشوند.
- هر یک از فیلدهایی که صرفا در Hive Metastore Schema موجود میباشد، به عنوان یک فیلد با قابلیت Nullablity در Schema به صورت Reconcile شده نیز اضافه می شود.
Refresh نمودن Metadata
Spark SQL برای دستیابی به عملکرد بهتر، اقدام به Cache کردن Metadataهای Parquet مینماید. در صورت فعال شدن فرآیند تبدیل در جدول Hive Metastore Parquet، Metadataهای مربوط به این جداول Convertشده نیز Cache میشوند. در صورت بهروزرسانی این جداول به وسیله Hive یا سایر ابزارهای خارجی، لازم است تا جداول مذکور به صورت دستی Refresh شوند تا ایجاد Metadataهای هماهنگ تضمین شود.
تعامل با نسخههای مختلف Hive Metastore
یکی از مهمترین بخشهای پشتیبانی Hive در Spark SQL، امکان تعامل با Hive Metastore میباشد که Spark SQL را جهت دسترسی به Metadataهای جداول Hive فعال میسازد. برای اجرای Query در نسخههای مختلف Hive Metastore میتوان از یک نسخهی باینری واحد از Spark SQL استفاده نمود که از Spark 1.4.0 شروع شده و از پیکربندی زیر استفاده مینماید. شایان توجه است که Spark SQL صرفنظر از نسخهی Metastore Hive به کارگرفته شده، در Hive 1.2.1 کامپایل شده و از این کلاسهای Serdes، UDF، UDAF و … برای اجرای داخلی استفاده مینماید.
JDBC برای سایر پایگاههای داده
Spark SQL شامل یک منبع داده میشود که با استفاده از JDBC میتواند به خواندن داده از پایگاههای داده دیگر بپردازد. این عملکرد نسبت به استفاده از JdbcRDD مناسبتر میباشد، زیرا نتایج به عنوان یک DataFrame ارائه شده و به سادگی در Spark SQL پردازش میشود یا به دیگر منابع داده متصل میگردند. همچنین برای منبع دادهی JDBC سادهتر است که از زبانهای Java یا Python استفاده نماید، در حالی که نیازی به ارائه ClassTag توسط کاربر وجود ندارد. باید توجه نمود که این موضوع از سرور Spark SQL JDBC متفاوت است؛ سروری که به برنامههای کاربردی دیگر اجازه میدهد تا Queryها را با استفاده از Spark SQL اجرا نمایند.
