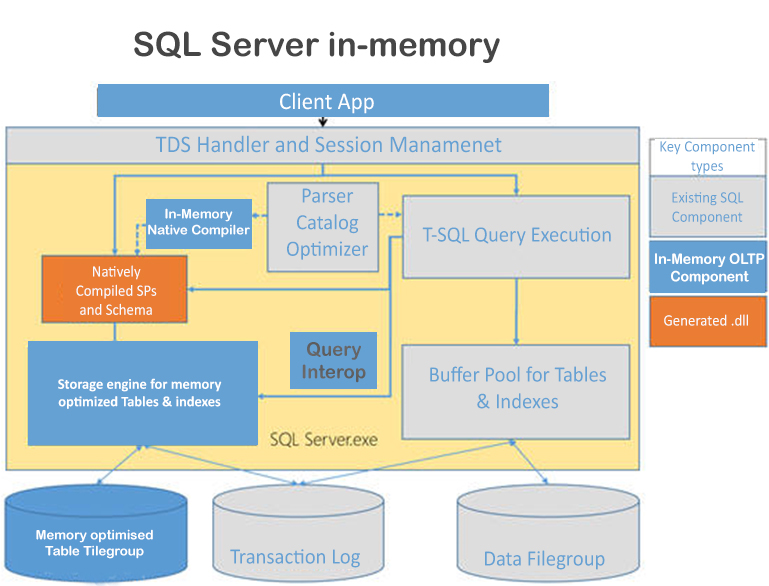
در قسمت اول از سری مقالات SQL Server In-Memory به بررسی بهبودهای ارائه شده در SQL Server پرداختیم. در این مقاله که قسمت دوم (پایانی) میباشد، به بررسی سایر قابلیتهای SQL Server In-Memory OLTP و In-Memory Columnstore و پیشرفتهای این تکنولوژی میپردازیم.

بهبودهای حاصل در زمینه همزمانی
برنامههای کاربردی که همزمانی در سطح موتور (Engine-Level) عملکرد آنها تحت تاثیر قرار میدهد (همچون Latch Contention یا Blocking)، در صورت انتقال به In-Memory OLTP بهبود قابل توجهی را تجربه میکنند. از آن رو که جداول Memory-Optimized هیچ صفحهای ندارند، هیچگونه Latchی وجود نداشته و درنتیجه هیچ انتظاری هم برای Latch وجود نخواهد داشت. چنانچه اپلیکیشن پایگاهداده در خلال عملیات خواندن و نوشتن با مشکل Blocking روبرو شود، In-Memory OLTP به دلیل استفاده از متد Optimistic Concurrency Control یا OCC برای دسترسی به دادهها، مشکل Blocking را از میان برمیدارد. OCC با استفاده از Row Versionها اجرا میشود اما این نسخهها برخلاف جداول Disk-Based به صورت In-Memory نگهداری میشود. از آن رو که دادههای جداول Memory-Optimized همواره به صورت In-Memory میباشند، انتظار و تاخیر ایجاد شده از طریق مسیر I/O از بین میرود. همچنین، انتظاری برای خواندن دادهها از دیسکها و یا برای Lockها در سطرهای داده وجود نخواهد داشت.
کامپایل نمودن Stored Procedure
SQL Server میتواند به صورت محلی به کامپایل نمودن Stored Procedureهایی که به جداول Memory-Optimized دسترسی دارند، بپردازد. این روش علاوه بر بهینهسازی TSQL، آنها را به کدهایی در زبان C تبدیل نموده و سپس یک DLL ایجاد میکند. SQL Server میتواند این روند را برای ایجاد کارایی بیشتر در ساختار منطقی کسبوکار، از طریق Stored Procedureهای جدید که در مقایسه با Stored Procedureهای قدیمی از دستورالعملهای کمتری استفاده مینمایند، به اجرا درآورد. نسخه SQL 14 به عبارات پرکاربرد TSQL موجود در بارکاری OLTP اجازه میدهد تا در Stored Procedureها به صورت Native استفاده شوند. تیم SQL Server همچنان به توسعه گستردهی TSQL در نسخههای جدید خود ادامه میدهند.
بررسی In-Memory Columnstore در SQL Server
In-Memory Columnstore به منظور کاهش قابل توجه تاثیر Storage تا میزان 10 برابر، از فرمت ذخیرهسازی به صورت ستونی (Columnar Storage Format) استفاده مینماید؛ این در حالی است که همچنان نیز میتواند عملکرد مطلوبتری را حتی به میزان 100 برابر در Queryهای قابل آنالیز ارائه کند. کاربر میتواند با استفاده از قابلیت فشردهسازی COLUMNSTORE_ARCHIVE برای دادههایی که کمتر مورد استفاده و رجوع قرار میگیرند، کارایی قابلیت فشردهسازی را تا 30 درصد افزایش دهد. در فرمت ذخیرهسازی ستونی، با ذخیرهی هر ستون به صورت جداگانه، قابلیت فشردهسازی قابل توجهی برای دادهها فراهم میگردد. از آنجا که دادههای یک ستون مشابه و اغلب تکراری میباشند، SQL Server میتواند به سطح بسیار بالایی از فشردهسازی داده دست یابد. افزایش میزان فشردهسازی با استفاده از حجم کمتری از فضای In-Memory موجب ارتقای بهبود عملکرد Queryها میشود. Queryهای آنالیز اغلب تنها چند ستون از جدول FACT را انتخاب میکنند. در فرآیند ذخیرهسازی ستونی فقط ستونهای مورد نیاز به حافظه وارد میشوند که بدین ترتیب استفاده از I/O حتی به میزان بیشتری نیز کاهش مییابد. این مورد برخلاف فرمت ذخیرهسازی مبتنی بر سطر میباشد که در آن همهی ستونها به عنوان بخشی از سطرها در حافظه ذخیره میشوند.
شاخصهای Columnstore به صورت کلاستری و غیر کلاستری
SQL Server 2014 از شاخصهایی کلاستری قابل بهروزرسانی Columnstore پشتیبانی مینماید که جایگزین جداول Rowstore سنتی میگردند. این شاخص به کاربران این امکان را میدهد تا علاوه بر اصلاح دادهها، آنها را به طور همزمان برای بارهای کاری انبار داده و سیستم پشتیبانی از تصمیمگیری یا به اختصار DSS، بارگذاری نمایند. با کاهش I/O و اجرای بهینه Queryها با استفاده از تکنیکهایی مانند کاربرد گزارهها در فرمت فشرده، پایین آوردن آنها و قرار دادن در لایه ذخیرهسازی در صورت امکان، بهرهگیری از معماری پردازشگرهای نوین و اجرای Batch جدید، تسریع در روند بهبود عملکرد Queryها تا 100 برابر ایجاد میشود.
علاوه بر موارد ذکر شده، SQL Server این امکان را نیز برای کاربران فراهم میکند تا شاخصهای غیر کلاستری Columnstore را در جداول Rowstore جهت آنالیزهای عملیاتی ایجاد نماید، که به عنوان نمونه میتوان از قابلیت آنالیز در Storeهای عملیاتی نام برد. لازم به ذکر است که شاخص غیرکلاستری Columnstore در SQL Server 2016 دارای قابلیت بهروزرسانی میباشند.
به طورکلی سطرها در شاخصهای Columnstore در یک مجموعه که شامل یک میلیون سطر میباشد، گروهبندی میگردند تا به قابلیت فشردهسازی بهینه برای دادهها دست یابند. این فرآیند گروهبندی سطرها، Rowgroup نیز نامیده میشود. در یک Rowgroup، مقادیر متعددی برای هر ستون به صورت LOBها فشرده و ذخیره میگردد. این واحدهای LOB اصطلاحا Segment خوانده شده و به عنوان واحد انتقال بین دیسک و حافظه به شمار میروند.
پردازش Query به صورت Batch
پردازش Query به صورت Batch، اساسا یک مکانیسم Vector-Based جهت اجرای Queryها میباشد که با شاخص Columnstore کاملا یکپارچه میشود. Queryهایی که شاخص Columnstore را هدف قرار میدهند، برای پردازش تا 900 سطر در کنار هم میتوانند از Batch-Mode استفاده نمایند و علاوه بر اجرای کارآمد Query موجب بهبود عملکرد آن به میزان 3 تا 4 برابر شوند. قابلیت پردازش Batch-Mode برای شاخصهای Columnstore به منظور بهرهمندی کامل از مزایای ساختاری و قابلیتهای In-Memory در SQL Server بهینهسازی میشود.
ـــــــــــــــــــــــــــــــــــــــــ
