
دستیابی به اطلاعات مفید و سودمند در میان حجم بسیار زیادی از دادهها و با توجه به روابط پیچیده دادهها با یکدیگر، امری دشوار میباشد. به کمک دادهکاوی میتوان اطلاعات بسیار مفید و سودمندی را از انبارهای داده استخراج کرده و جهت بهبود کسبوکار از آنها استفاده نمود. در قسمتهای اول و دوم از سری مقالات دادهکاوی یا Data Mining به بررسی مفهوم دادهکاوی و مراحل دادهکاوی پرداختیم. در این مقاله به بررسی سایر مراحل فرآیند دادهکاوی میپردازیم.

منظور از مدلسازی دادهکاوی یا Data Mining
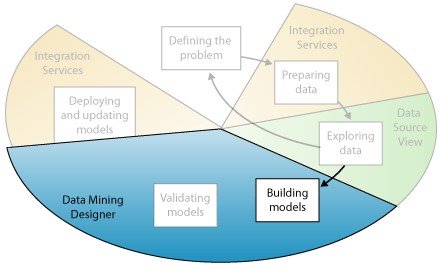
همانطور که در تصویر زیر مشاهده میشود، مرحلهی چهارم در فرآیند دادهکاوی یا Data Mining
به ارائه مدل یا مدل هایی برای کاوش اختصاص دارد.
ستونهایی از دادهها که برای استفاده در نظرگرفته شدهاند را میتوان با ایجاد یک ساختار دادهکاوی یا Mining Structure، تعریف نمود. هرچند ساختار داده کاوی، به منبع دادهها مرتبط میگردد اما در واقع تا قبل از پردازش، شامل هیچ دادهای نمیشود و در هنگام پردازش نمودن ساختار داده کاوی، Analysis Services میتواند اطلاعات گردآوری شده و سایر اطلاعات آماری مورد استفاده برای آنالیز را ارائه نماید. ضمن اینکه این اطلاعات در هر مدل دادهکاوی ساختاریافته نیز مورد استفاده قرار میگیرد.
پیش از پردازش ساختار و مدل، مدل دادهکاوی نیز تنها یک ظرفیت خالی محسوب میشود که مشخصکنندهی ستونهای مربوط به دادههای ورودی، صفات یا Attributeهای پیشبینیشده و پارامترهایی میباشد که نحوهی پردازش دادهها توسط الگوریتم را معین میکند. پردازش یک مدلِ اغلب Training یا آموزشی نامیده میشود و در واقع فرآیندی است جهت بهکارگیری یک الگوریتم ریاضی خاص برای دادههای یک ساختار و هدف آن، استخراج الگوها میباشد. نوع الگوهای یافت شده در روند Training به مواردی همچون انتخاب دادههای Training، الگوریتم انتخاب شده و چگونگی پیکربندی الگوریتم بستگی دارد. SQL Server 2016 شامل تعداد زیادی از الگوریتمهای مختلف میباشد که هریک با نوع متفاوتی از امور تناسب داشته و هرکدام مدل متفاوتی را ایجاد مینمایند.
علاوه بر موارد فوق این امکان نیز وجود دارد تا از پارامترهایی جهت تنظیم هر الگوریتم استفاده شود، همچنین میتوان از فیلترها در دادههای آموزشی بهره گرفته و به این وسیله صرفا از یک زیرمجموعه از دادهها استفاده نمود که منجر به نتایج متفاوتی نیز خواهد شد. Object متعلق به مدل داده کاوی پس از عبور دادهها از مدل، شامل خلاصهها و الگوهایی است که قابلیت استفاده یا Query برای فرآیند پیشبینی را دارا میباشد. کاربر با استفاده از Data Mining Wizard در SQL Server Data Tools یا با کاربرد زبان Data Mining Extensions DMX میتواند یک مدل جدید را تعریف نماید.
بیشتر بخوانید: بررسی مدلهای دادهکاوی و سرویسهای آنالیز – قسمت اول
این نکته را باید در نظر داشت که همراه با تغییرات دادهها، باید ساختار و مدل دادهکاوی بهروزرسانی گردد. هنگامی که Mining Structure از طریق پردازش مجدد بهروزرسانی میشود، Analysis Services اقدام به بازیابی دادهها از منبع مینماید که شامل هر گونه داده جدید در صورت بهروزرسانی منبع به شکلی پویا میشود و محتوای ساختار دادهکاوی یا Data Mining را مورد بازنگری قرار میدهد. در صورت وجود مدلهای مبتنی بر ساختار، این امکان وجود دارد که فقط همین مدلها برای بهروزرسانی انتخاب شود؛ بدین معنا که فرآیند Train کردن فقط برای دادههای جدید صورت گیرد و یا اینکه مدل به همان صورت حفظ شود.
جستجو و تایید اعتبار مدلها
در مرحله پنجم از فرآیند دادهکاوی همانطور که در نمودار زیر نشان داده شده است، روند جستجوی مدلهایی است که ایجاد شده و اثربخشی آنها مورد بررسی قرار گرفته است.
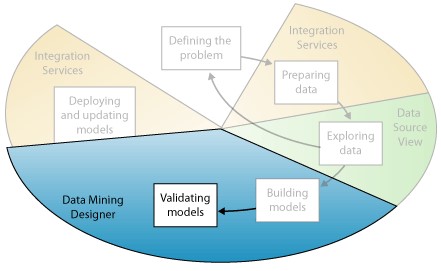
پیش از پیادهسازی مدل در محیط عملیاتی باید نحوه عملکرد آن مورد بررسی قرار گیرد. به علاوه در هنگام تهیه مدل معمولا باید چندین مدل با پیکربندیهای متفاوت ارائه شوند تا پس از تست نمودن آنها بتوان به مدلی دست یافت که بهترین نتیجه را در ارتباط با مشکلات و دادهها فراهم میآورد.
بیشتر بخوانید: بررسی مدلهای دادهکاوی و سرویسهای آنالیز – قسمت دوم (پایانی)
Analysis Services به ارائه ابزارهایی میپردازد که تقسیم دادهها به دو مجموعه دادهی Testing و Training را میسر نموده و بدین ترتیب امکان ارزیابی دقیق عملکرد در تمام مدلهای مربوط به دادههای مشابه را فراهم مینماید. بدین ترتیب میتوان از مجموعه دادههای Training برای ایجاد مدل و از مجموعهدادههای Testing برای بررسی دقت مدلها از طریق ایجاد Queryهای پیشبینی، استفاده نمود. در SQL Server 2016 Analysis Services یا به اختصار (SSAS)، این تقسیمبندی به صورت خودکار و در حین ارائه مدل انجام میپذیرد.
امکان جستجوی روندها و الگوهای شناساییشده توسط الگوریتمها با استفاده از Viewerهای موجود در Data Mining Designer در SQL Server Data Tools میسر میگردد. همچنین میتوان کیفیت پیشبینی مدلها را با بهرهگیری از ابزارهایی در Designer مانند ماتریس دستهبندی و Life Chart تست نمود.
استفاده از تکنیکهای آماری در دادهکاوی یا Data Mining
تکنیکهای آماری با نام Cross-Validation به ایجاد زیرمجموعههایی از دادهها به صورت خودکار و تست مدلها در هر زیرمجموعه کمک می کند، به این ترتیب میتوان اطمینان حاصل نمود که مدل مورد نظر به دادههای مشخصی اختصاص داشته و ممکن است برای فرآیندهای استنتاجی برروی کل جمعیت مورد استفاده قرار گیرد.
چنانچه هیچیک از مدلهای ایجاد شده در مرحلهی ایجاد مدل یا Building Models به خوبی عمل نکنند، لازم است که به مرحله قبلی فرآیند رجوع و مسئله مجددا تعریف گردد و یا اینکه دادهها در مجموعه اصلی دادهها مجددا مورد بررسی قرارگیرند.
پیادهسازی و بهروزرسانی مدلها
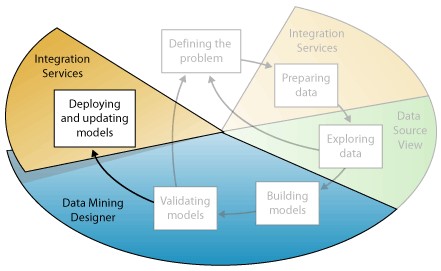
طبق نمودار زیر، آخرین مرحله در فرآیند دادهکاوی به پیادهسازی مدلهایی اختصاص دارد که بهترین عملکرد را در محیط عملیاتی داشتهاند.
پس از استقرار Mining Model در یک محیط عملیاتی میتوان عملکردهای بسیاری را با توجه به نیازها اجرا نمود. در زیر به برخی از این عملکردها اشاره میشود:
- استفاده از مدلها برای فرآیندهای پیشبینی که ممکن است در مراحل بعدی برای اتخاذ تصمیمات در کسبوکار نیز به کار گرفته شود. SQL Server به ارائهی زبان DMX برای ایجاد Queryهای پیشبینی و Prediction Query Builder برای کمک به انجام Query میپردازد.
- انجام Queryهای محتوا به منظور بازیابی اطلاعات آماری، قواعد یا فرمولهای مربوط به مدلها
- جایگذاریِ مستقیم عملکرد دادهکاوی در برنامههای کاربردی: بدین ترتیب میتوانAnalysis Management یا Objects AMO را شامل نمود که دربردارنده مجموعهای از Objectهای مورد استفاده در برنامهکاربردی برای ارائه، تغییر، پردازش و حذف ساختارها و مدلهای دادهکاوی است. ضمن اینکه امکان ارسال مستقیم پیامهای XML for Analysis XMLA به یکی از Instanceهای Analysis Services نیز وجود دارد.
- استفاده از Integration Services برای ارائه Packageی که از مدل داده کاوی برای تفکیک هوشمندانه دادههای ورودی در قالب چندین جدول استفاده مینماید. برای مثال چنانچه یک پایگاهداده برای مشتریان بالقوه به طور پیوسته بهروزرسانی میشود، میتوان از یک Mining Model همراه با Integration Services بهره برده و داده های ورودی کاربران را به دو دسته تقسیم نمود که کاربران احتمالی خریدار و غیرخریدار محصول را دربر دارد.
- ارائه گزارشی که امکان Query نمودن مستقیم در مدل داده کاوی موجود را برای کاربران فراهم میکند.
- بهروزرسانی مدلها پس از بازنگری و آنالیز: هر یک از این بهروزرسانی مستلزم پردازش مجدد مدلها میباشد.
- به روزرسانی پویای مدلها همگام با افزایش میزان دادههای ورودی به سازمان و ایجاد تغییرات مداوم با هدف بهبود اثربخشی راهکار که باید بخشی از استراتژی پیادهسازی باشد.
ــــــــــــــ
مفهوم داده کاوی (Data Mining) و نحوه کارکرد آن – قسمت اول
مفهوم داده کاوی (Data Mining) و نحوه کارکرد آن – قسمت دوم
مفهوم داده کاوی (Data Mining) و نحوه کارکرد آن – قسمت سوم (پایانی)
