با توجه به افزایش روزافزون حجم دادهها و تاثیرگذاری آنها بر کسب و کارها، انجام آنالیزهای دقیق و کاربردی اهمیت ویژهای یافته است. دادهکاوی چیست؟ با استفاده از دادهکاوی یا Data Mining میتوان مدلهای مورد نظر خود را بر اساس دادههای موجود ایجاد نمود. در قسمت اول از این سری مقالات به بررسی مفهوم Data Mining و مراحل ساخت مدل پرداختیم. در این مقاله که قسمت دوم از این سری مقالات میباشد، به بررسی ادامه مراحل ایجاد مدل دادهکاوی میپردازیم.

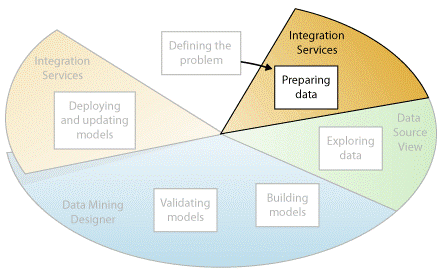
آمادهسازی دادهها
مطابق نمودار زیر، در مرحله دوم از روند دادهکاوی به تجمیع و پاکسازی دادههایی پرداخته میشود که در مرحلهی تعریف مسئله شناسایی شدهاند.
دادهکاوی چیست؟ دادهکاوی به فرآیند کشف و شناسایی اطلاعات عملیاتی در مجموعههای بزرگ داده اطلاق میشود. این امکان وجود دارد که دادهها در سراسر سازمان توزیع شده و در قالبهای مختلف ذخیره گردند و یا اینکه ممکن است شامل تناقضات و ناسازگاریهایی از جمله ورودیهای نادرست یا از دست رفته باشند. برای مثال ممکن است دادهها نشاندهندهی این موضوع باشند که خرید محصول توسط کاربر پیش از عرضهی آن در بازار صورت میگیرد یا مشتری همواره از فروشگاهی خرید میکند که بیش از 3 کیلومتر از محل زندگی وی فاصله دارد.
فرآیند پاکسازی دادهها یا Data Cleaning تنها به حذف دادههای نامناسب یا وارد کردن مقادیر از دست رفته خلاصه نمیشود، بلکه کشف روابط پنهانشدهی میان دادهها، شناسایی دقیقترین منابع داده و تعیین مناسبترین ستونها برای استفاده در آنالیز را نیز دربر میگیرد. برای مثال میتوان به مواردی از این دست که از بین تاریخ ارسال محموله یا تاریخ دریافت سفارش، کدام یک مدنظر قرار گیرد و یا اینکه از میان دو پارامتر قیمت کل و تخفیف کدام یک به عنوان موثرترین عامل در افزایش فروش به شمار میروند، اشاره نمود. لازم به ذکر است که دادههای ناقص، دادههای نادرست و دادههای ورودی به ظاهر مجزا اما در حقیقت بسیار بههمپیوسته و مرتبط با یکدیگر، میتوانند تاثیری فراتر از حد انتظار بر روی نتایج داشته باشند.
بنابراین پیش از اقدام به ایجاد مدلهای دادهکاوی Mining Model باید به شناسایی این مسائل و نحوهی پاسخگویی به آنها پرداخته شود. دادهکاوی چیست؟ با توجه به اینکه فرآیند دادهکاوی معمولا برروی حجم بالایی از مجموعه دادهها انجام شده و امکان بررسی کیفیت دادهها برای هر تراکنش وجود ندارد، احتمالا استفاده از برخی روشهای پروفایل نمودن دادهها و همچنین استفاده از ابزارهای پاکسازی و فیلترینگ خودکار آنها ضرورت مییابد؛ به عنوان مثال میتوان از محصولاتی همچون Integration Services ،Microsoft SQL Server 2012 Master Data Services و یا SQL Server Data Quality Services نام برد که قابلیتهایی جهت جستجوی دادهها و کشف تناقضات و ناهماهنگیها فراهم مینمایند.
بیشتر بخوانید: آشنایی با الگوریتمهای دادهکاوی یا Data Mining
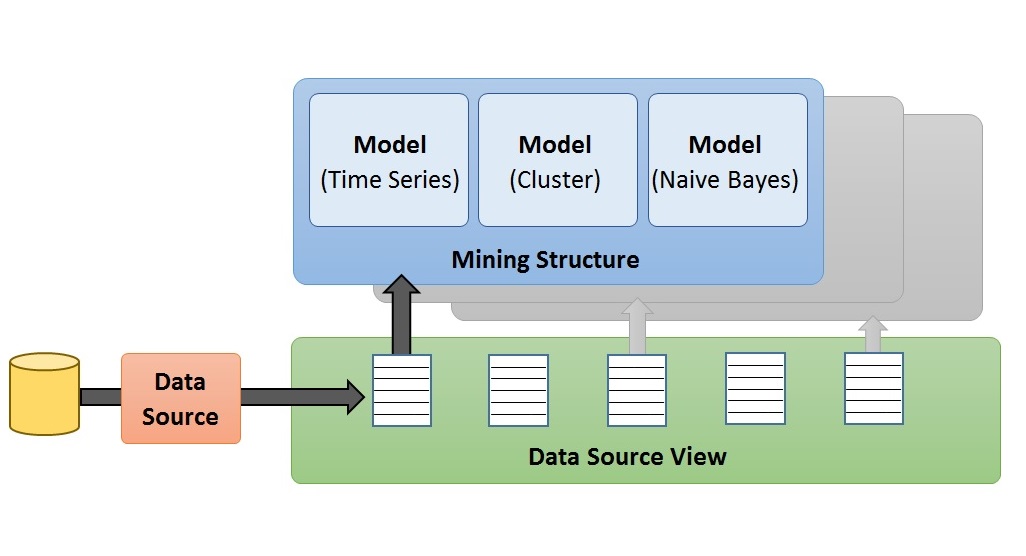
دادهکاوی با استفاده از منابع داده
لازم به ذکر است که الزامی در رابطه با ذخیرهی دادههای مورد استفاده در Data Mining بر روی یک پایگاهدادهی Cube OLAP و یا Relational Database وجود ندارد، اگرچه میتوان از هردوی آنها به عنوان منبعهای داده استفاده نمود. بنابراین فرآیند دادهکاوی را میتوان با استفاده از هر منبع دادهای که به عنوان منبع دادهی Analysis Services تعریف شده باشد، انجام داد. این منابع داده ممکن است شامل فایلهای متنی و Workbookهای Excel یا دادههای سایر منابع خارجی باشد.
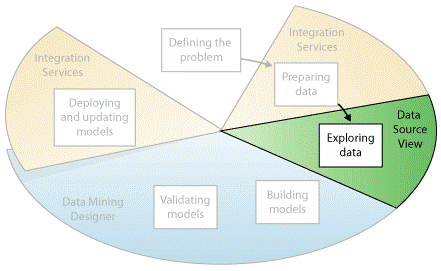
منظور از جستجوی دادهها در دادهکاوی چیست
مطابق نمودار زیر، جستجوی دادههای آمادهشده به عنوان سومین مرحله از روند دادهکاوی محسوب میشود.
کاربران برای اتخاذ تصمیمهای مناسب در هنگام ایجاد مدلهای داده کاوی باید به درک صحیحی از دادهها برسند. از جمله تکنیکهای جستجو میتوان به محاسبهی حداقل و حداکثر مقادیر، محاسبهی میانگین و انحراف معیار و توجه به توزیع دادهها اشاره نمود. به طور مثال، این امکان وجود دارد تا با بازنگری حداقل، حداکثر و میانگین مقادیر به این نتیجهگیری دستیافت که دادهها قادر به نمایش فرآیندهای مرتبط با مشتریان یا کسبوکار نبوده و از همین رو نیاز به کسب دادههای متوازنتر یا بازنگری فرضیاتی است که انتظارات بر مبنای آن شکل گرفته است. با توجه به انحراف معیار و سایر مقادیر توزیعی میتوان به اطلاعات مفیدی دربارهی ثبات و دقت نتایج دست یافت. انحراف معیار بالا ممکن است نشانهی آن باشد که افزایش میزان دادهها میتواند به بهبود مدل کمک نماید. دادههایی که انحراف زیادی از توزیع استاندارد داشته باشند احتمالا خطا دارند، بدین معنا که تصویر دقیقی از یک مسئله در دنیای واقعی ارائه میدهند اما تناسب و هماهنگی مدل با دادهها را دشوار مینمایند.
بیشتر بخوانید: بررسی مراحل تست و اعتبارسنجی در دادهکاوی (Data Mining)
با جستجوی دادهها بر اساس درک شخصی از مسائل کسبوکار میتوان در مورد مجموعه دادههای دارای دادههای معیوب تصمیمگیری نمود و سپس به تدوین یک استراتژی مناسب برای حل مساله یا درک عمیقتر از رفتارهای معمول در کسبوکار پراخت.
استفاده از ابزارهایی همچون Master Data Services این امکان را فراهم میکند تا منابع دادهی قابلدسترس کاملا بررسی گردیده و در خصوص دسترسپذیری آنها برای دادهکاوی تصمیمگیریهای لازم صورت پذیرد. با بهکار گیری ابزارهایی همچون SQL Server Data Quality Services یا Data Profiler در Integration Services نیز میتوان به بررسی توزیع دادهها و حل مشکلاتی همچون خطا یا دادههای از دست رفته پرداخت.
پس از تعریف منابع باید با استفاده از Data Source View Designer در SQL Server Data Tools به ترکیب آنها در ساختار Data Source پرداخته شود. این ابزار طراحی نیز به نوبهی خود از ابزارهای متعددی بهره میبرد که برای جستجوی دادهها و تایید قابلیت کاربرد آن برای ایجاد مدل به کار میرود.
نکتهی قابلتوجه اینکه Analysis Service در هنگام طراحی مدل به صورت خودکار اقدام به ارائهی خلاصههای آماری از دادههای موجود در مدل مینماید که بدین ترتیب کاربر میتواند برای ارائه گزارش یا آنالیزهای بیشتر، Query خود را ارسال نماید.
ــــــــــــــ
مفهوم داده کاوی (Data Mining) و نحوه کارکرد آن – قسمت اول
مفهوم داده کاوی (Data Mining) و نحوه کارکرد آن – قسمت دوم
مفهوم داده کاوی (Data Mining) و نحوه کارکرد آن – قسمت سوم (پایانی)
